Building a Solid Data Preprocessing Pipeline
Posted by melllow thomas
Filed in Technology 267 views
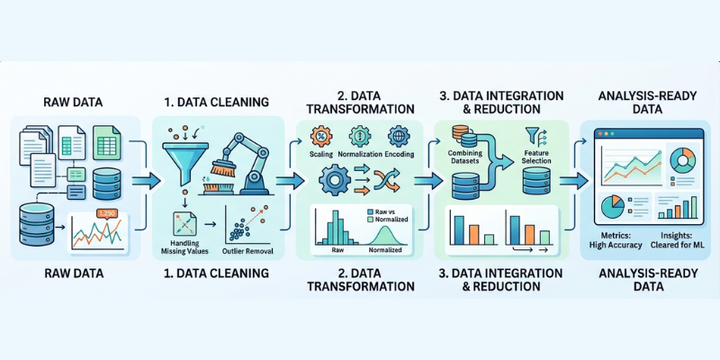
Data preprocessing is one of the most important steps in any data science project. Raw data is often incomplete, inconsistent, and noisy, which makes it unsuitable for analysis or modeling. An organized preprocessing pipeline aids in converting this unrefined data into a tidy and functional format. It also ensures that your results are reliable and easier to interpret.
For beginners, understanding preprocessing can make a huge difference in how confidently they approach real-world datasets. Learning these skills early helps build a strong foundation for advanced techniques later on. If you are looking to build these skills in a guided way, you can consider enrolling in a Data Science Course in Trivandrum at FITA Academy to gain practical exposure and structured learning support.
Understanding the Role of Data Cleaning
The first step in any preprocessing pipeline is data cleaning. This involves identifying missing values, correcting errors, and removing duplicates. Well-organized data guarantees that your analysis relies on precise information instead of deceptive inputs.
Handling missing data requires careful decisions. You can either remove incomplete records or fill them using statistical methods like mean or median. The choice depends on the dataset and the problem you are solving. Consistency in formatting is also important, especially when dealing with dates, categories, or numerical values.
Transforming Data for Better Analysis
Once the data is clean, the next step is transformation. This process includes scaling, normalization, and encoding categorical variables. These techniques help standardize the data so that machine learning models can interpret it effectively.
Feature scaling guarantees that all variables fall within a comparable range, enhancing the performance of the model. Encoding converts categorical data into numerical form, making it easier for algorithms to process. If you want to understand these concepts in depth and apply them to real projects, you can explore a Data Science Course in Kochi to strengthen your practical knowledge with guided exercises.
Handling Outliers and Inconsistencies
Outliers can significantly impact the outcome of your analysis. These are data points that differ greatly from the rest of the dataset. Identifying and treating outliers is crucial for maintaining the quality of your results.
You can detect outliers using statistical methods or visualization techniques. Once identified, they can either be removed or adjusted depending on the context. At the same time, resolving inconsistencies in naming conventions or units ensures uniformity across the dataset. This step helps avoid confusion during later stages of analysis.
Building a Reusable Pipeline
A solid preprocessing pipeline is not just about cleaning data once. It should be reusable and consistent across different datasets. Automation plays a crucial role in this situation, as it minimizes the need for human labor and lowers the chances of errors.
Creating a sequence of well-defined steps allows you to apply the same transformations every time new data is introduced. This consistency improves efficiency and ensures that your models receive data in the same format. It also makes your workflow more organized and easier to maintain over time.
Building a solid data preprocessing pipeline is essential for any successful data science project. It lays the groundwork for accurate analysis and reliable model performance. By prioritizing cleaning, transformation, and consistency, you can greatly enhance the quality of your results.
For those who want to deepen their understanding and gain hands on experience, it is a good idea to take the next step and enroll in a Data Science Course in Pune to strengthen your skills and work on datasets with confidence.
Also check: Probability Theory Basics for Data Science